Explainable Action Prediction through Self-Supervision on Scene Graphs
Abstract
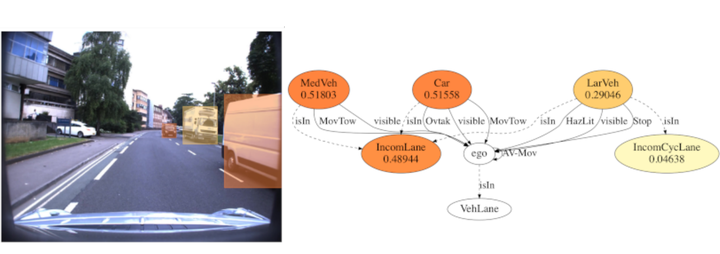
This work explores scene graphs as a distille representation of high-level information for autonomous driving, applied to future driver-action prediction. Given the scarcity and strong imbalance of data samples, we propose a self-supervision pipeline to infer representative and well-separated embeddings. Key aspects are interpretability and explainability; as such, we embed in our architecture attention mechanisms that can create spatial and temporal heatmaps on the scene graphs. We evaluate our system on the ROAD dataset against a fully-supervised approach, showing the superiority of our training regime.
Publication
In 2023 IEEE International Conference on Robotics Automation (ICRA)