Smooth Grad-CAM++: An Enhanced Inference Level Visualization Technique for Deep Convolutional Neural Network Models
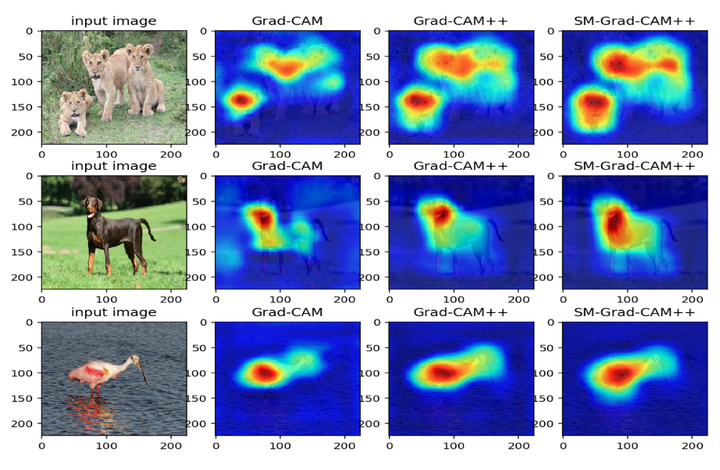 Different gradient based visualisations
Different gradient based visualisations
Abstract
Gaining insight into how deep convolutional neural network models perform image classification and how to explain their outputs have been a concern to computer vision researchers and decision makers. These deep models are often referred to as black box due to low comprehension of their internal workings. As an effort to developing explainable deep learning models, several methods have been proposed such as finding gradients of class output with respect to input image (sensitivity maps), class activation map (CAM), and Gradient based Class Activation Maps (Grad-CAM). These methods under perform when localizing multiple occurrences of the same class and do not work for all CNNs. In addition, Grad-CAM does not capture the entire object in completeness when used on single object images, this affect performance on recognition tasks. With the intention to create an enhanced visual explanation in terms of visual sharpness, object localization and explaining multiple occurrences of objects in a single image, we present Smooth Grad-CAM++, a technique that combines methods from two other recent techniques—SMOOTHGRAD and Grad-CAM++. Our Smooth Grad-CAM++ technique provides the capability of either visualizing a layer, subset of feature maps, or subset of neurons within a feature map at each instance at the inference level (model prediction process). After experimenting with few images, Smooth Grad-CAM++ produced more visually sharp maps with better localization of objects in the given input images when compared with other methods.